
Cassandra
Cassandra는 대규모의 데이터를 빠르게 처리하기 위해 설계된 오픈소스 분산형 NoSQL 데이터베이스이다.
처음 페이스북에서 밭은 편지함 검색 기능을 위해 개발되었으며, 현재는 애플, 넷플릭스, 우버 등 대규모 트래픽을 다루는 글로벌 기업들의 핵심 데이터베이스로 사용되고 있다.
작동 구조
카산드라는 서버 1대에만 설치해서 쓰는 프로그램이 아니다. 최소 3대 이상의 서버에 똑같이 설치한 뒤, 이들을 네트워크로 연결해 하나의 거대한 그룹으로 묶어서 사용한다.
- 여러 대의 서버가 원형으로 연결되어 함께 일하는 구조이다.
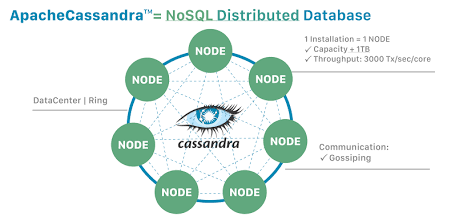
| 출처: Apache Cassandra | Apache Cassandra Documentation |
분업의 원리
여러대의 서버가 프로그램의 로직을 나누는 것이 아닌 데이터만 나눈다.
- 프로그램이 데이터 100만개를 저장하라는 명령을 받으면 10개의 서버가 데이터를 쪼갠 뒤 각자의 구역에 저장을 한다.
- 프로그램은 카산드라 서버 중 아무에게나 요청하면 그 서버가 알아서 데이터가 있는 진짜 서버를 찾아 결과를 갖다준다.
서버를 여러대를 사용하는 이유
백업 및 시스템의 확장을 위해
- 데이터를 1대의 서버에만 두지 않고 항상 2~3대의 다른 서버에 자동으로 복사해 둔다. 서버 1~2대가 없어져도 데이터는 안전하며, 서비스는 멈추지 않는다.
- 넷플릭스나 우버처럼 데이터가 폭주하는 경우 비싼 서버 한대가 아닌, 저렴하고 평범한 일반 서버를 계속 추가하기만 하면 처리 능력과 용량이 늘어난다.
정리
카산드라는 “서버는 언젠가 반드시 고장 나며, 데이터는 끝없이 많아진다”는 전제하에 만들어졌다. 저렴한 여러 대의 서버를 묶어, 서버가 죽지 않으면서도 많은 양의 데이터를 빠르게 저장하고 꺼내주는 서버 역할을 하는 것이 바로 아파치 카산드라이다.
Leave a comment